
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 요양 보호사 자격증 시험 날짜
- 텐서 플로우 자격증
- 요양 보호사 시험 어렵 나요
- 패스트캠퍼스업스테이지에이아이랩
- google tensorflow 자격증
- 요양 보호사 자격증 개요
- Tensorflow 자격증
- 패스트캠퍼스AI부트캠프
- 텐서 플로우 자격증 합격
- 요양 보호
- 요양 보호사
- 텐서 플로 자격증
- 텐서 플로우 자격증 난이도
- 국시원 요양 보호사
- 요양 보호사 신청
- UpstageAILab
- 텐서 플로우 자격증 공부
- 요양 보호사 자격증 취득 방법
- upstageailab#국비지원
- 업스테이지패스트캠퍼스
- 요양 보호사 자격증
- 패스트캠퍼스
- 패스트캠퍼스업스테이지부트캠프
- AI부트캠프
- 국비지원
- 텐서 플로우 자격증 수기
- 보호사
- sqlp 강의
- 텐서 플로우 자격증 준비
- 구글 텐서 플로우 자격증
- Today
- Total
공부법에 관한 모든 것
[Ai lab] 자료구조 본문
균형 이진 트리란 모든 노드 간의 높이 차이가 1 이하인 이진 트리를 의미한다.
도입의 필요성
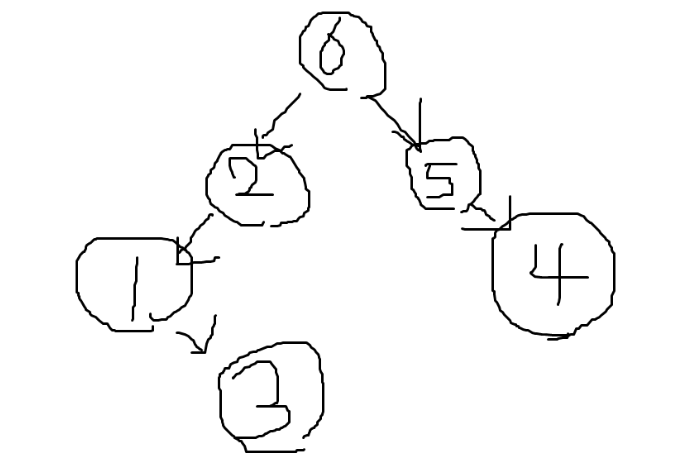
균형 이진 트리의 필요성은 무엇일까? 이진 트리 탐색은 시간 복잡도가 낮다. 그러나 항상 시간 복잡도가 낮을까? 아니다. 만약 부모 노드 값이 말도 안되게 크다면 즉 그림 1과 같은 상황이 되고 그러한 경우 시간 복잡도는 O(log n)에서 O(n)이 된다.

그림 1. 이진 트리가 최악의 시간 복잡도를 가지는 경우
이런 균형이 꺠진 이진 트리를 다시 균형 잡히게 만들기 위해 AVL 기법이 등장하였다.
균형 이진 트리란
균형 이진 트리란 어떠한 노드를 부모 노드라 간주했을 때 부모 노드 기준으로 왼쪽 노드들과 오른쪽 노드들의 개수의 차이가 1 이하가 된 상태를 말한다. 가령 위의 그림1 에서 10은 균형이 잡힌 상태이다. 왼쪽 노드의 개수: 0, 오른쪽 노드의 개수: 0 이기에 둘을 뺴도 1 이하기 떄문이다. 비슷한 논리로 100 역시 균형이 잡힌 상태이다. 왼쪽 노드의 개수: 1, 오른쪽 노드의 개수: 0 이기에 둘을 뺴도 1이하기 떄문이다. 그러나 1만, 1억 노드는 균형이 깨진 상태이다.
균형이 꺠진 경우의 일반화
균형이 꺠진 상태인 경우들은 어떤 것들이 있을까. 다음 4가지 경우로 일반화가 가능하다.

구현이 완료됐을떄 작동 과정.
Height = 1
9J
Height = 2
9J
8I
Height = 2
8I
7H 9J
Height = 3
8I
7H 9J
6G
Height = 3
8I
6G 9J
5F 7H
Height = 3
6G
5F 8I
4E 7H 9J
Height = 3
6G
4E 8I
3D 5F 7H 9J
Height = 4
6G
4E 8I
3D 5F 7H 9J
2C
Height = 4
6G
4E 8I
2C 5F 7H 9J
1B 3D 트리가 만들어지는 과정에서 균형이 맞춰지는 방식으로 만들어진다.
이진 트리 탐색이란 이진 트리 구조의 수형도에서 특정한 값을 찾는 작업을 말한다. 이때 규칙이 있는데 시작 노드의 값이 5이면 그 다음 노드의 값이 5보다 작은 경우 왼쪽에 위치하고 5보다 큰 경우에는 오른쪽에 위치한다. 그 뒤로 오는 노드들도 이러한 규칙에 따라서 분배된다.
이렇게 분기가 나뉘기 때문에 더 낮은 시간복잡도를 가진다.

그러나 만약 시작 노드 값이 비이상적으로 크거나 작은 값이여서 이후에 들어오는 모든 노드의 값들이 한쪽 방향으로 쏠린다면 그러한 경우의 한하여 최악의 시간 복잡도를 가지게 된다.

시작 노드의 값이 100
이진 트리란 각 노드가 최대 2개의 자식 노드를 가지는 자료구조를 말한다. 지금까지 배운 다른 자료구조들은 모두 데이터가 하나씩 연결이 되어 있었다. 가령 연결 리스트를 예로들면 한 노드가 다른 노드 1개랑만 연결이 되어있다. 이런 식으로 일렬로 연결된 자료구조를 선형(Linear) 자료구조라고 한다.
두 개의 노드와 연결된 양방향 연결 리스트라는 녀석도 있는데 그런 자료형들은 비선형 자료구조라고 하고 가장 대표적인 비선형 자료구조는 이진 트리이다.
이진 트리 구현 및 형태 시각화
현재 만드려는 트리의 모양은 다음과 같다.
덱 자료구조 설명
핵심 함수는 총 4가지로 다음과 같다.
- PushFront
- PushBack
- PopFront
- PopBack
함수의 이름에서 알 수 있듯이 각각 순서대로 원소를 시작 부분에 추가하는 기능, 원소를 끝 부분에 추가하는 기능, 시작 부분에 원소를 Pop하는 기능, 끝 부분에 원소를 Pop하는 기능을 수행한다.
그런데 PushBack은 이전에 포스팅에서 다룬 큐 자료구조의 enqueue함수와 기능이 동일하고 popfront는 dequeue 함수와 기능이 동일한 것을 확인할 수 있다. 그렇기에 deque를 구현할 때 queue class를 상속받아서 구현한다.
큐(Queue)란 먼저 들어온 사람이 먼저 처리되는 즉 선착순으로 처리되는 구조를 가르키는 일반적인 단어이다.

주문한 음식이 나와서 A가 받으러 나갔고 그다음 음식을 받으러 B가 나갔다. 이때 가게에 새로운 사람 E가 들어왔다. E는 어느 자리에 앉아야 할까?
당장 생각해볼 수 있는 경우는 2가지이다. c와 d의 값을 복사해서 앞으로 땡기고 인덱스 2 자리에 e를 넣는 것이다. 혹은 배열의 크기를 키워서 인덱스 4 자리에 e를 넣는 것이다. 후자의 경우를 택한다면 배열의 크기가 무한정으로 계속 늘어날 것이고 앞에는 비어있는 원소들이 계속 생겨날 것이다. 전자를 택하는 것도 후자의 비하면 합리적이긴 하지만 이미 있는 공간을 놔두고 굳이 원소를 복사하여 옮기는 안해도 될 연산을 한다.
E를 그냥 인덱스 0 자리에 넣어주면 어떨가. 별개의 작업을 할 필요가 없지 않는가. 물론 누가 먼저 들어온 것인지는 헷갈릴 것이다. 이런 상황을 방지하려면 정수형 변수 2개를 만들어서 앞(front)과 뒤(rear)가 어딘지 명확하게 기록하면 된다.
원형 큐
front라는 정수형 변수는 가장 먼저 들어온 수의 인덱스보다 1 작은 값을 가지고 있다. rear라는 정수형 변수는 가장 마지막에 들어온 수의 인덱스 값을 가지고 있다. front값과 rear값이 같아지면 빈 큐라는 의미이다. 그렇기 때문에 총 용량이 n인 원형 큐가 담을 수 있는 정보의 개수는 n - 1개이다.
만약 주워진 용량을 초과하여 손님이 온다면 rear의 값은 큐가 마치 원형으로 이어진 것처럼 0이 된다. 이를 코드로 구현하면 다음과 같다. rear = (rear +1) % capacity (capacity는 용량이라는 뜻이다.)

위와 같은 상황에서 손님 D가오면 !! 별 수 없습니다... capacity 값을 늘려야합니다. 문제는 그러면 순서를 다시 선형으로 되돌려줘야한다는 점에 있습니다.

스택이란
컴퓨터 과학 및 프로그래밍에서 사용되는 중요한 데이터 구조 중 하나이다. 스택은 데이터 요소를 저장하고 검색하는 데 사용되는 선형 데이터 구조로, 데이터 요소를 쌓아 올리는(LIFO, Last-In-First-Out) 방식으로 작동한다. 이번 포스팅에서는 스택에 대한 개념 이해와 스택 자료형을 구현해보는 시간을 가져볼 것이다.
스택의 요소
스택 자료형은 하나의 컨테이너이다. 컨테이너란 데이터를 저장할 수 있는 자료형을 말하는데 대표적으로 그동안 배운 배열(리스트) 자료형이 있다. 배열은 특정 원소에 임의로 접근하는 것이 자유롭지만 꽤 복잡한 데이터를 다룰 때는 번거로운 측면이있다. 스택 자료형은 급식판을 생각하면 되는데 데이터를 꺼내쓸 때 맨 위의 있는 급식판을 꺼내듯이 스택 자료형에서 데이터를 꺼낼 때는 가장 나중에 들어온 데이터만을 꺼내 사용할 수 있다.
순열이란 나열할 수 있는 모든 경우의 수를 말한다. 가령 1 2 3을 나열할 수 있는 모든 경우의 수는
1 2 3
1 3 2
2 1 3
2 3 1
3 1 2
3 2 1
총 6가지이다. 재귀 호출을 활용하여 순열 알고리즘을 구현해보자.
도식화

빨간색은 Swap을 의미하고 녹색은 코드가 실행되는 순서를 의미한다.
2단계에서는 첫 앞자리는 고정이고 뒤의 자리만 Swap을 해주는 것을 확인할 수 있다.
그러니깐 이걸 보면 앞자리가 고정이고 뒤에 두 자리가 Swap되는 식이다.
a b c
a c b
b a c
b c a
c b a
c a b원상복구를 해주는 작업도 잊지 않고 해줘야 한다.
이진 탐색이란 배열에서 값을 찾으려고 할 때 효율적으로 찾을 수 있는 방법들 중 하나이다.
이진 탐색
0부터 9까지의 값이 순차적으로 저장된 배열에서 숫자 5의 인덱스 값을 찾으려고 한다고 가정하자. 이때 순차 탐색을 시도하면 0번부터 하나씩 찾다가 5에 도달할 것이기 때문에 총 6번의 연산을 수행할 것이다. 이진 탐색은 배열의 중간으로 들어가 탐색을 시작한다.
Ex)
0~9의 중간값은 4이다. 인덱스 4의 값 4는 5보다 작기 때문에 그러면 인덱스 0~4까지의 모든 값을 무시한다.
남아있는 인덱스 5~9의 중간값은 7이다. 인덱스 7의 값 7은 5보다 크기 떄문에 인덱스 7~9까지의 모든 값을 무시힌다.
남아있는 인덱스 5~6의 중간값은 5이다. 인덱스 5의 값 5는 찾고자하는 값과 일치하기에 탐색을 중단한다.
Ex) 만약 찾고자하는 값이 배열에 존재하지 않는다고 가정하면 left 값이 right값보다 커지는 지점이 존재한다.(혹은 반대의 경우) 이 경우 탐색을 중단하면 된다.
이진 탐색이란 배열에서 값을 찾으려고 할 때 효율적으로 찾을 수 있는 방법들 중 하나이다.
이진 탐색
0부터 9까지의 값이 순차적으로 저장된 배열에서 숫자 5의 인덱스 값을 찾으려고 한다고 가정하자. 이때 순차 탐색을 시도하면 0번부터 하나씩 찾다가 5에 도달할 것이기 때문에 총 6번의 연산을 수행할 것이다. 이진 탐색은 배열의 중간으로 들어가 탐색을 시작한다.
Ex)
0~9의 중간값은 4이다. 인덱스 4의 값 4는 5보다 작기 때문에 그러면 인덱스 0~4까지의 모든 값을 무시한다.
남아있는 인덱스 5~9의 중간값은 7이다. 인덱스 7의 값 7은 5보다 크기 떄문에 인덱스 7~9까지의 모든 값을 무시힌다.
남아있는 인덱스 5~6의 중간값은 5이다. 인덱스 5의 값 5는 찾고자하는 값과 일치하기에 탐색을 중단한다.
Ex) 만약 찾고자하는 값이 배열에 존재하지 않는다고 가정하면 left 값이 right값보다 커지는 지점이 존재한다.(혹은 반대의 경우) 이 경우 탐색을 중단하면 된다.
한 함수에서 자기 자신을 호출하는 것을 재귀 호출이라고 한다. 재귀에 대해서 배우면서 가장 조심해야 될 부분은 재귀로 호출된 함수와 호출한 함수는 이름과 기능만 같을 뿐 별개의 함수라는 점이다. 다음을 보자.
다른 함수를 호출하는 함수
void Func2()
{
int i = 2;
cout << "Fun2 is called" << i << endl;
}
void Func1()
{
int j = 2;
cout << "Fun1 is called" << j << endl;
Func2();
}
int main()
{
Func1();
//출력
//Fun1 is called2
//Fun2 is called2
}main 함수에서 Func1을 호출하고 Func1에서 Func2가 호출된다. 이후 Func2가 종료되고 Func1이 종료되고 main 함수가 종료된다. 재귀 호출도 똑같다. 다만 Func1과 Func2가 같다는 사실만이 차이점이다.
재귀 호출 함수
void RecurFunc(int cnt)
{
if (cnt == 0) return;
cout << cnt << endl;
RecurFunc(cnt - 1);
}
int main(){
//기본 재귀 함수
int a = 4;
RecurFunc(4);
}RecurFunc라는 함수는 내부에서 RecurFunc를 호출하고 있다. 이때 반드시 함수 내부에 종료 조건이 설정되어있어야 한다. 그러하지 않다면 무한히 자신을 호출할 것이기 떄문이다.
위의 함수도 재귀 호출을 할 떄 cnt값을 하나 줄여주면서 전달을 해주기 때문에 cnt가 0이 되는 순간 가장 나중에 호출된 함수가 종료될 것이고 이후 순차적으로 함수들이 종료가 될 것이다.