
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- 보호사
- AI부트캠프
- 요양 보호사
- 업스테이지패스트캠퍼스
- 요양 보호사 자격증 시험 날짜
- 텐서 플로우 자격증 수기
- 구글 텐서 플로우 자격증
- 요양 보호사 신청
- 패스트캠퍼스업스테이지에이아이랩
- google tensorflow 자격증
- 텐서 플로 자격증
- 텐서 플로우 자격증 준비
- upstageailab#국비지원
- 요양 보호사 자격증 취득 방법
- 요양 보호사 자격증 개요
- 요양 보호사 시험 어렵 나요
- sqlp 강의
- 국시원 요양 보호사
- 패스트캠퍼스
- 패스트캠퍼스업스테이지부트캠프
- 요양 보호사 자격증
- 텐서 플로우 자격증 공부
- 패스트캠퍼스AI부트캠프
- 텐서 플로우 자격증 합격
- 요양 보호
- Tensorflow 자격증
- 텐서 플로우 자격증
- UpstageAILab
- 국비지원
- 텐서 플로우 자격증 난이도
- Today
- Total
공부법에 관한 모든 것
[ai lab] Computer Vision 본문
Vision의 정의
: 시각으로 보이는 이미지 등을 숫자(tensor, RGB)로 시각화
Computer Vision
: vision 데이터들에서 의미있는 정보를 추출하고 이를 이해하여 작업을 수행하는 것.
단계
- Low Level (image processing)
o) Resize : 주위의 pixel들만을 고려하여 resize 작업
o) Color Jitter : 각 필셀들의 RGB 변경 (독립적이기 때문에 L-LV에 속함.)
o) Edge Dectection : 주위 pixel 값이 바뀌면 edge로 간주.
- Mid Level
o) panorama stitching
: 이미지 합치기 (대응점을 찾아야되서 Lv Up)
o) Muti-view Stereo
: 여러 각도의 2D -> 3D / 질감 구성 (대응점 고려, Lv Up)
- High Level
o) image classification
o) object detection
o) segmentation
활용 사례
- pose estimation, re-identification, action recognition, ocr, medical image analysis, GAN, Virtual Try On, NeRF, image to video ... etc
고전 컴퓨터 비전
- motive) 결과의 후처리 / 가공 단계에서는 아직도 쓸만하다.
morphological transformation
- Erosion (경계를 침식 / 축소)
작동 원리) 커널 나래가 모두 1이면 1로 filltering Else 0

무서워 !
- Dilation (경계를 팽창)
작동 원리) 하나라도 1이면 1로 Else 0
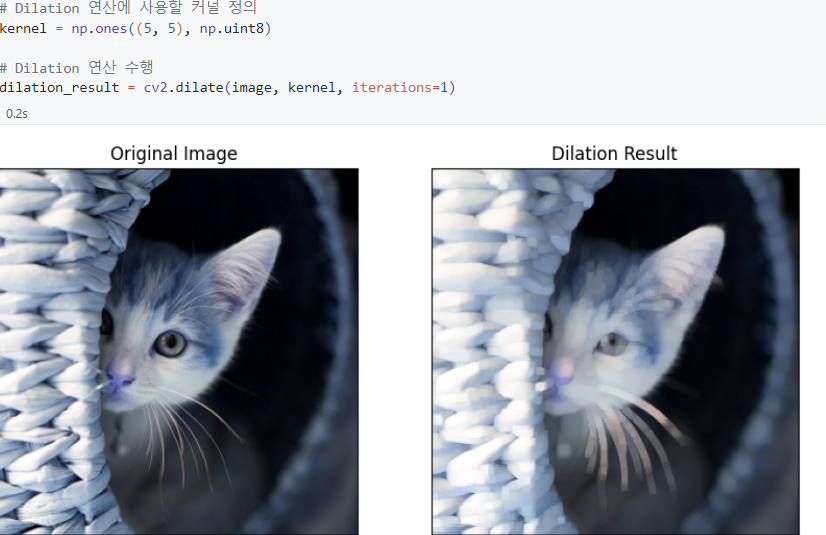
화장 지운 version
- Opening
작동 원리) Erosion(노이즈 제거) -> Dilation (사이즈 복원)
Contour Detection
: 같은 색깔 및 intensity를 가지는 연속적인 경계로 이루어진 curve 추론
- 중요성
딥러닝을 위한 데이터셋 구축에 활요 가능 + 적은 데이터 + 적은 비용
Conny Edge Detection
- 과정
1) 노이즈 제거
: '그림이 자글자글' -> 학습에 악영향 -> 가우시안 필터를 사용하여 제거
2) 높은 미분값 사용
: 열/행 방향으로 pixel 값 변화 정도
3) 최댓값이 아닌 지점 '0'으로 치환 (Non Maximum Suppresion)
4) Hyper_parms 조절로 Edge Detect (output은 binary IMG)
cf) opencv 라이브러리의 findcontours ()

모델 구성
- visual Feature
: 이미지에서 특징을 추출
- backbone
: 주어진 Task를 수행할 수 있는 압축된 visual feature를 산출하는 것
모델 구조
: 여러개의 layers -> 고차원 / 앞의 Layer를 활용한다.
Decoder의 역활
: visual features를 목표하는 task의 출력을 만드는 과정

- task가 classification인 경우 decoder의 형태
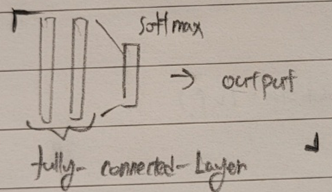
BxCxWxH
BackBone -> (BCWH) -> (BC) -> (B x N of Classes, scores) -> solfmax(scores) , 0~1 사이로 정규화 -> output
- task가 Detection인 경우 decoder의 형태

고양이/강아지일 확률 뿐만 아니라 위치를 탐지해야하기 때문에 좌표에 대한 값도 output에 포함이 되어있다.
- task가 Segmentation인 경우 decoder의 형태
: 해당하는 영역을 픽셀 단위로 출력함.
conclusion) Task에 따라 output / decoder가 다르다. 그러나 공통된 feature를 뽑는 backbone은 동일하게 사용 가능하다.
backbone
: CNN(fillter + bias)
input(img) X fillter + bias
- stride : fillter가 한 번에 몇칸 움직일까
- padding : feature map의 크기를 일정하게 유지하기 위해 임의로 pixel 추가
-> normaly) zero-padding 사용
output_size : (N - F + 2P) / S + 1
cf) Padding을 넣어줄 수 있기 때문에 conv 연산을 무한히 할 수 있다.
Q) pooling을 하는 이유가 무엇일까?
1. 파라미터의 수가 줄어든다. 2. receptive field(수용 영역)가 달라진다.
컴퓨터 비전 모델의 변천
Alexnet
: 최초의 이미지 분류 모델
- 특징
: receptive field는 감소하는 down sampling 기법을 사용한다. 또 channel 수는 증가한다.
- overfitting 방지
: data augmentation(다양한 방식으로 학습 데이터 수 늘리기), drop out(학습에 임의 뉴런 배제하기)
VDG
- 특징
: small fillters(3 x 3으로 fix) , deep networks
- 징점
3 x 3 Conv 3개가 7 x 7 Conv 1개와 표현값이 동일, 대신 전자가 layer가 더 깊기에 non_lineratlity가 커짐.
ResNet
- motive
: VDG 모델을 사용하면 Layer가 일정 수준 이상으로 깊어지면 성능이 안좋게 나옴. 이게 overfitting은 아닌게 train set에서도 성능이 안좋게 나옴.
- 구조
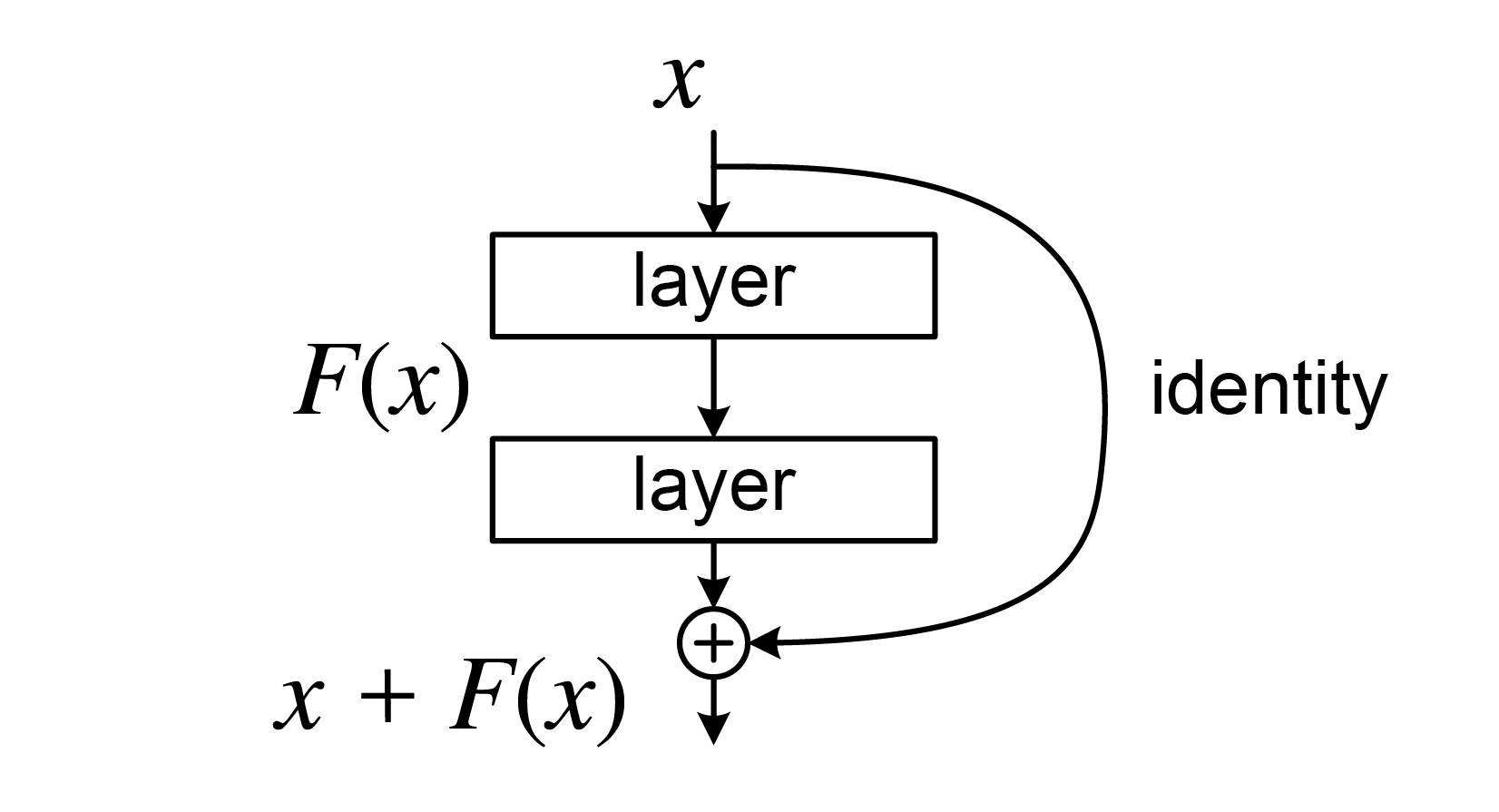
활성화 함수에 넣은 값 + 원래 값이 출력이 됨. 이러면 성능이 엄청나게 올라감. why?
이상적인 함수(H(x))를 만드는게 쉬울까 아니면 x + H(x)를 만드는게 쉬울까? 바로 후자가 더 쉬움.
if) H(x)가 x로 근사한다고 가정하면 h(x) - x 는 0에 근사함. 또 가중치를 초기화 할 때는 보통 0 근처 값으로 초기화를 함. 그렇기에 0 근처의 값을 만드는 것은 쉬움.
Q) H(x)가 왜 x로 근사함?
Layer가 깊을수록 이상적인 상황은 이미지를 조금씩 조금씩 업데이트하는 것이 이상적이다. -> 즉 이상적으로 흘러가는 경우에 각 층마다의 변화가 크지 않을 것이다. -> 한 층마다에 x의 변화량만 업데이트하면 되니깐 아주 효과적으로 학습을 할 수 있게 된다는 것이다 ~
bottleneck layer
: Channel 의 차원을 축소하는 layer
- 작동
: 1 x 1 Conv를 사용하면 in / output 간에 Dim을 맞추면서 parms가 줄어든다.
ex)

Batch Norm
: conv -> BN -> ReLU <- ResNet 모델 구조는 다음과 같다.
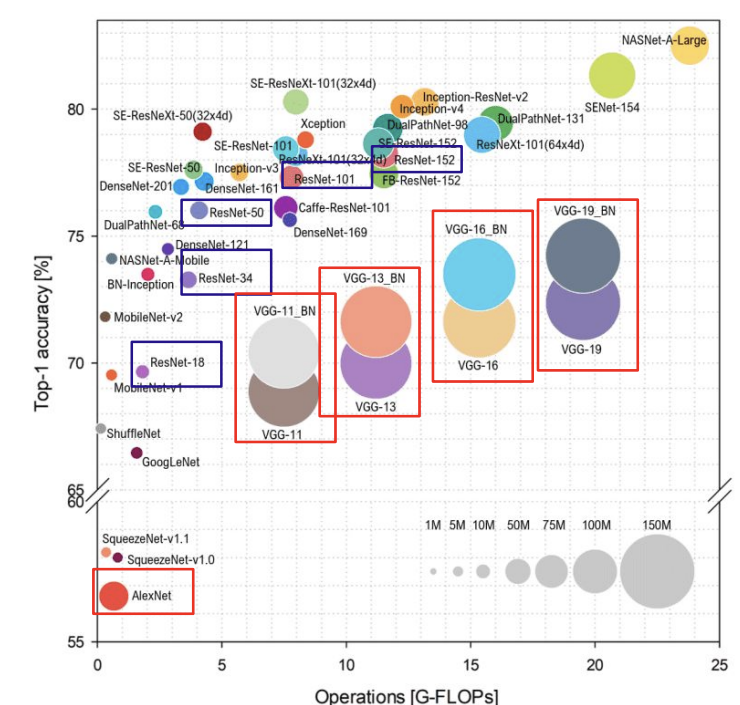
x축이 학습에 필요한 데이터량, y축이 정확도
- ## #####